AI Agents in Fraud Detection: Bridging the Gap Between Traditional Machine Learning and Human Reasoning

In an era where digital transactions dominate, fraud has evolved into a sophisticated, ever-present threat. By 2026, global fraud losses are projected to reach $43 billion, with identity theft occurring every 14 seconds in the U.S. alone. As criminals harness artificial intelligence (AI) to launch unprecedented attacks, businesses face an urgent question: How can they stay ahead in this high-stakes arms race?
Today, we will explore how AI agents — when equipped with a traditional machine learning model and a reasoning large language model engine are making fraud detection more explainable and robust.
Here is a live demonstration of the AI agent system in action:
The Growing Challenge of Fraud
A Crisis of Scale and Sophistication
Consider these staggering statistics:
- 134 million Americans will experience credit card fraud in their lifetime.
- Phishing attacks remain on the upswing into 2024. Q3 2024 saw 932,923 attacks, up from ~877,536 in Q2
- Deepfake scams have drained millions from businesses, with synthetic voices mimicking CEOs to authorize fraudulent transfers.
It is an arms race: Fraudsters are scaling operations with AI-driven card testing, evading detection, and exploiting zero-day vulnerabilities while defenders (the good guys) need equally or better adaptive tools to stay one step ahead of the curve.
The issue is fraudsters are adapting faster than institutions where legacy systems are struggling to keep pace. The main limitations of these systems are:
- Rules-Based Engines: Rigid “if-then” logic fails against novel attack patterns.
- Machine Learning: While ML models excel at detecting known fraud patterns, they’re “black boxes” offering no explanation for decisions. Worse, they falter against data drift — shifts in transaction behavior that render historical data obsolete.
How Traiditional ML Combined with Reasoning Engines Can Make Fraud Detection More Efficient
The Rise of Agentic AI
AI agents are autonomous systems that reason, learn, and act using tools like APIs and databases. Unlike static ML models, they can:
- Analyze Context: Cross-reference transactions with user history, location, and market trends.
- Self-Improve: Use reinforcement learning (RL) to adapt to new threats.
- Explain Decisions: Generate plain-language reports (e.g., “A $316 grocery charge at 2 AM in a city 34 miles from the user’s home is suspicious”).
- Behavioral Analysis: Detect subtle red flags (e.g., rushed checkout flows, mismatched billing/shipping addresses).
For this article, we are going to equip the agent with a traditional ML model as well as a reasoning engine for better explainability of the transaction.

Training the machine learning model
To train our ML model, we are going to use the publicly available data on credit card transactions from Kaggle: https://www.kaggle.com/datasets/kartik2112/fraud-detection
The dataset has over a million fraudulent and nonfraudulent credit card transactions.
In the following, we will briefly explain the steps to train the ML model:
- The first step is to remove any unnecessary features such as first name, last name, date of birth, etc.
- Next, we label and encode the textual features such as the merchant name, category, and street.
- Finally, we scale our features, define our predicted labels (is_fraud=0 or 1), split the data into train and test sets, and train the machine learning model Isolation Forest.
Make sure to save the model at the end so it can be used by our agent as a tool later on.
# Import necessary libraries
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
import joblib
from sklearn.metrics import classification_report
# Save the trained model to a file
# Load the dataset
data = pd.read_csv('Fraud/fraudTrain.csv')
data.head()
data.drop_duplicates()
# Drop any columns that are not useful (e.g., transaction IDs)
data = data.drop(columns=["Unnamed: 0", "first", "last", "state", "city_pop", "job", "dob"])
# Encode categorical variables
# Label encode binary categorical features (e.g., gender)
encoder = LabelEncoder()
data["merchant"] = encoder.fit_transform(data["merchant"])
data["category"] = encoder.fit_transform(data["category"])
data["street"] = encoder.fit_transform(data["street"])
data["trans_num"] = encoder.fit_transform(data["trans_num"])
data["city"] = encoder.fit_transform(data["city"])
data["gender"] = encoder.fit_transform(data["gender"])
data["trans_date_trans_time"] = encoder.fit_transform(data["trans_date_trans_time"])
#Save the encoder (this will allow you to load it during predictions)
joblib.dump(encoder, 'label_encoder.pkl')
# Separate features (X) and target variable (y)
X = data.drop(columns=['is_fraud'])
y = data['is_fraud']
# Split the data into training and testing sets (70% train, 30% test)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Scale numerical features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
joblib.dump(scaler, 'scaler.pkl')
X_test_scaled = scaler.transform(X_test)
from sklearn.ensemble import IsolationForest
# Train the Isolation Forest model (assume 1% fraud cases, so set contamination accordingly)
model = IsolationForest(contamination=0.03, random_state=42)
model.fit(X_train_scaled)
# Make predictions on the test set
# IsolationForest returns -1 for anomalies (fraud) and 1 for normal transactions
y_pred = model.predict(X_test_scaled)
# Convert predictions (-1 for fraud -> 1, and 1 for non-fraud -> 0)
y_pred = [1 if x == -1 else 0 for x in y_pred]
print(classification_report(y_test, y_pred))
joblib.dump(model, 'fraud_model.pkl')Let’s test the model on a sample transaction:
# Import necessary libraries
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
import joblib
import json
from sklearn.metrics import classification_report
# Load the saved model from the file
model = joblib.load('fraud_model.pkl')
# Load the dataset
transaction = '''{
"trans_date_trans_time": "2019-12-09 03:23:21",
"cc_num": 2266735643685262,
"merchant": "Koepp-Parker",
"category": "grocery_pos",
"amt": 316.82,
"first": "Carlos",
"last": "Chung",
"gender": "M",
"street": "8957 Russell Key",
"city": "Grant",
"state": "AL",
"zip": 35747,
"lat": 34.4959,
"long": -86.259,
"city_pop": 5901,
"job": "Curator",
"dob": "1972-07-25",
"trans_num": "1e787b206a1a9154a5f397dfaa6f6b40",
"unix_time": 1355023401,
"merch_lat": 35.177042,
"merch_long": -86.942305
}
'''
# Convert the JSON string into a dictionary
transaction_data = json.loads(transaction)
transaction_data = {key: value for key, value in transaction_data.items() if key not in ["first", "last", "state", "city_pop", "job", "dob","is_fraud"]}
df = pd.DataFrame([transaction_data])
# Apply the same preprocessing used in training:
encoder = joblib.load('label_encoder.pkl')
#encoder = LabelEncoder()
# Encode categorical variables
df["merchant"] = encoder.fit_transform(df["merchant"])
df["category"] = encoder.fit_transform(df["category"])
df["street"] = encoder.fit_transform(df["street"])
df["trans_num"] = encoder.fit_transform(df["trans_num"])
df["city"] = encoder.fit_transform(df["city"])
df["gender"] = encoder.fit_transform(df["gender"])
df["trans_date_trans_time"] = encoder.fit_transform(df["trans_date_trans_time"])
scaler = joblib.load('scaler.pkl')
# Scale the numerical features (same scaler used during training)
df_scaled = scaler.transform(df)
# Use the trained model to predict if the transaction is fraudulent
y_pred = model.predict(df_scaled)
#print(y_pred)
# Convert the prediction (-1 for fraud -> 1, and 1 for non-fraud -> 0)
is_fraud = 1 if y_pred[0] == -1 else 0
print(f"Fraudulent Transaction: {is_fraud}")Fraudulent Transaction: 0
Setting up The LLM to Analyze Transactions
The next tool we are going to equip the agent with is a reasoning LLM that will analyze the transaction and determine if it is fraudulent or not based on the details of the transaction and the previous purchase history.
We are going to use the Deepseek model for the LLM as it has a longer chain of thoughts and advanced reasoning capabilities (for more information, check out this benchmark):
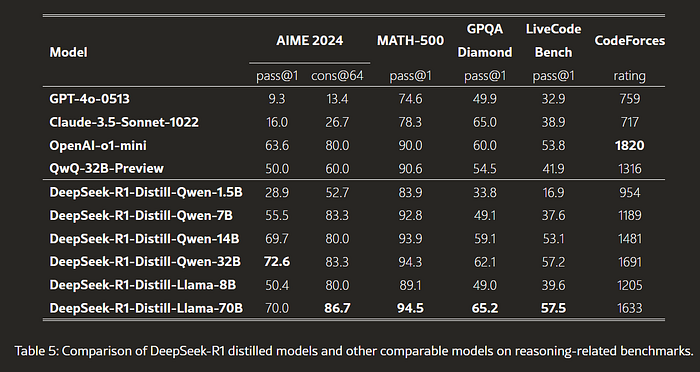
For this tutorial, we are going to use DeepSeek-R1-Distill-Llama-70B API from the UbiAI platform. Using UbiAI, we can log and evaluate the response of the LLM for each query which will be critical later on to improve the model with reinforcement learning later on.
Make sure to set monitor_model: True to be able to track the model response for each query.
Let’s test the model in the UbiAI playground:
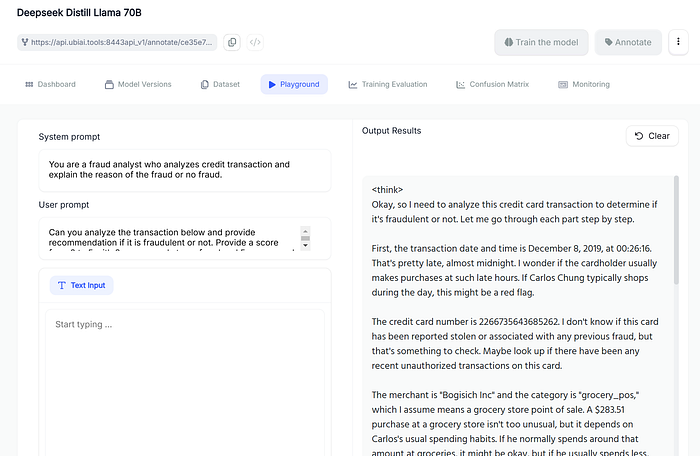
Seems to be working correctly, here is the full response of the Deepseek model:
<think>
Okay, so I need to analyze this credit card transaction to determine if it's fraudulent or not. Let me go through each part step by step.
First, the transaction date and time is December 8, 2019, at 00:26:16. That's pretty late, almost midnight. I wonder if the cardholder usually makes purchases at such late hours. If Carlos Chung typically shops during the day, this might be a red flag.
The credit card number is 2266735643685262. I don't know if this card has been reported stolen or associated with any previous fraud, but that's something to check. Maybe look up if there have been any recent unauthorized transactions on this card.
The merchant is "Bogisich Inc" and the category is "grocery_pos," which I assume means a grocery store point of sale. A $283.51 purchase at a grocery store isn't too unusual, but it depends on Carlos's usual spending habits. If he normally spends around that amount at groceries, it might be okay, but if he usually spends less, this could be suspicious.
Looking at the location details, the transaction is in Grant, AL, with a zip code of 35747. The latitude and longitude are 34.4959, -86.259. The merchant's location is at 35.189602, -86.344231. I should check if these locations make sense. If Carlos was in or near Grant, AL, around that time, it's probably legitimate. But if he was somewhere else, especially far away, that's a problem.
The cardholder's personal info: Carlos Chung, male, born July 25, 1972. His job is a curator, which might mean he has a stable income, but that doesn't necessarily mean it's not fraud. His address is 8957 Russell Key, Grant, AL. I should verify if this matches the billing address on file.
The transaction number is "1dac0908859f67f9d27638bc11df5119" and the unix time is 1354926376. I can convert that unix time to a date to cross-verify. Let me do that real quick. Unix time 1354926376 corresponds to December 8, 2012. Wait, that's odd because the trans_date is 2019-12-08. There's a discrepancy here. The unix time is from 2012, but the transaction date is 2019. That doesn't make sense. Maybe it's a typo or a mistake in the data, but it's worth noting.
The city population is 5901, which is pretty small. If Carlos lives in a small town and shops locally, the transaction might be normal. But if he's from a bigger city, this could be odd.
Putting it all together, the main red flags are the late transaction time and the mismatched unix time. The amount isn't too high, but the timing and location need to be checked. If Carlos wasn't in Grant, AL, or if the unix time is correct but doesn't match the transaction date, it could indicate fraud. I should also check the card's history for any other suspicious activity around that time.
I think I'll give this a fraud score of 3. There are some suspicious points, but without more context, it's not a definite fraud. It's worth investigating further, especially the location and time discrepancies.
</think>
**Fraud Analysis and Recommendation**
**Transaction Overview:**
- **Date and Time:** December 8, 2019, at 00:26:16 (late night)
- **Merchant:** Bogisich Inc (grocery store)
- **Amount:** $283.51
- **Location:** Grant, AL (zip 35747)
- **Cardholder:** Carlos Chung
**Red Flags Identified:**
1. **Late Transaction Time:** The purchase occurred near midnight, which is unusual if the cardholder typically shops during the day.
2. **Mismatched Unix Time:** The unix time corresponds to December 8, 2012, not 2019, indicating a potential error or manipulation.
**Investigation Recommendations:**
- Verify the cardholder's location on the transaction date.
- Check the card's history for similar late-night transactions.
- Investigate the cause of the unix time discrepancy.
- Cross-reference the transaction location with the cardholder's known whereabouts.
**Fraud Score:** 3/5
- The transaction has suspicious elements, particularly the timing and date discrepancy, warranting further investigation. However, without additional context, it's not conclusively fraudulent.
**Conclusion:**
While the transaction raises some concerns, particularly regarding timing and date inconsistencies, further investigation is needed to determine if it's fraudulent.The transaction analysis is thorough in identifying late transaction time, comparing the location of the merchant and the cardholder and the amount. However, we will need to provide it with historical transactions to improve the quality of the analysis.
Setting up The Fraud Detection AI Agent
There are few platforms that let you build AI agenst such as crewai, relevance.ai, n8n, langflow, and so on. But for this tutorial, we are going to use Kudra AI to create the agent due to its ability to handle multiple document types (PDF, TXT, HTML, etc.) and enable users to upload create a document database that we can feed to the agent:

The first step is to upload historical transactions that the agent can use for its analysis. In Kudra, we can do so by uploading txt files to our Agent project as shown in the figure.
Next, we need to create two tools:
- Fraud_detector_ML: Traditional ML model API to predict if the transaction is fraudulent or not
- Transaction_explanator: LLM reasoning engine API to reason about current and purchase history to determine if it is fraudulent or not.
Within Kudra, we connect these two APIs as tools to the agent. We can add other tools to help the agent investigate further such as a Google Map API to locate the merchant's location, a website scraper to fetch information about the merchant, and so on. But for the sake of the tutorial, we are going to only give it 2 tools.
4. The Power of Explainability
To test the agent, we are going to test this specific transaction with 10 most recent purchases from the same cardholder:
{ “trans_date_trans_time”: “2019–12–09 03:23:21”, “cc_num”: 2266735643685262, “merchant”: “Koepp-Parker”, “category”: “grocery_pos”, “amt”: 316.82, “first”: “Carlos”, “last”: “Chung”, “gender”: “M”, “street”: “8957 Russell Key”, “city”: “Grant”, “state”: “AL”, “zip”: 35747, “lat”: 34.4959, “long”: -86.259, “city_pop”: 5901, “job”: “Curator”, “dob”: “1972–07–25”, “trans_num”: “1e787b206a1a9154a5f397dfaa6f6b40”, “unix_time”: 1355023401, “merch_lat”: 35.177042, “merch_long”: -86.942305}
Below is a screenshot of the AI Agent output:
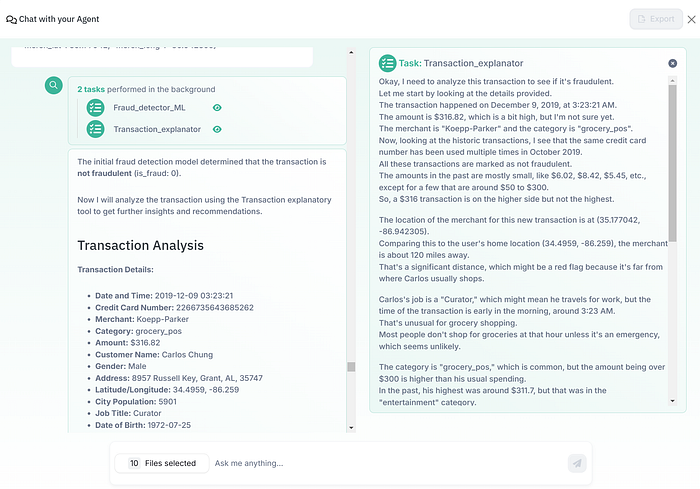
We can see that the agent first called the first tool Fraud_detector_ML then the second tool Transaction_explanator.
Here is the output of the predictive ML model: {‘is_fraud’: 0}. Meaning the transaction is not fraudulent.
However, if you look at the output of the LLM reasoner, we see a different story:
Fraud Analysis Report
Transaction Details:
Date & Time: December 9, 2019, 3:23:21
Merchant: Koepp-Parker
Category: Grocery
Amount: $316.82
Location: 35.177042, -86.942305 (approximately 34 miles from home)
Analysis: 1.
Transaction Time: The transaction occurred early in the morning, which may be unusual but isn’t conclusive evidence of fraud without additional context. 2.
Amount: The amount is significantly higher than typical transactions, with most being under $100.
A previous large purchase of $311.70 was in the entertainment category, making this grocery purchase notable. 3.
Merchant Category: The category differs from the previous large transaction, raising questions about the nature of the purchase. 4.
Location: The merchant is located 34 miles from the cardholder’s home, which is a significant distance and not consistent with past transaction locations.Conclusion: The combination of a high amount, different merchant category, and distant location suggests potential fraudulent activity.
While there could be legitimate reasons, these anomalies warrant further investigation.Recommendation: Flag as potentially fraudulent.
The LLM’s report included:
- Time analysis (“The transaction occurred early in the morning which is unusual”).
- Geographic mismatch (analyzed the distance different between merchant and cardholder of 34 miles).
- Amount (Higher amount compared to typical transaction).
The analysis was very thorough comparing the current transaction details to the previously known transaction and finding out discrepancies.
The final recommendation was to flag the transaction as fraudulent which is in contradiction with the traditional black-box ML model.
At this point, we have two contradictory pieces of information, and the tie-breaker could be equipping the agent with additional tools or bringing the human-in-the-loop to review.
By adding a reasoning LLM engine in addition to the traditional ML model, we have:
- Reduced the black box aspect of traditional ML model
- Adder extra verification layer using LLM reasoning
- Improved the efficiency of the system overall
As the next steps, we can even add multiple agents working together to provide a more precise recommendation as it has been shown that multi-agent systems perform better than single agents.
It is worth noting that generic LLMs are not consistent and reliable due to their generative nature (as opposed to traditional predictive ML). For example, I fed the same transactions 10 times and 2 out of 10 the output was “not fraudulent”. This is a common issue in generative AI space and will require fine-tuning the model with reinforcement learning which we will discuss in the next section.
LLM Tracing, Evaluation, and Reinforcement Learning:
Continuous Monitoring
LLMs are notoriously known to be inconsistent and unreliable due to their generative nature. From the reliability standpoint, it is imperative to log and monitor the interaction with the LLM for the following purposes:
- Analyze input/output to measure any data drift
- Find any anomalies in the output
- Rate the response of the LLM with human or another LLM as a judge for reward data collection that can be used to improve the model with reinforcement learning training.
Using UbIAI, each API call is logged in the “Monitoring” section with the input/output.

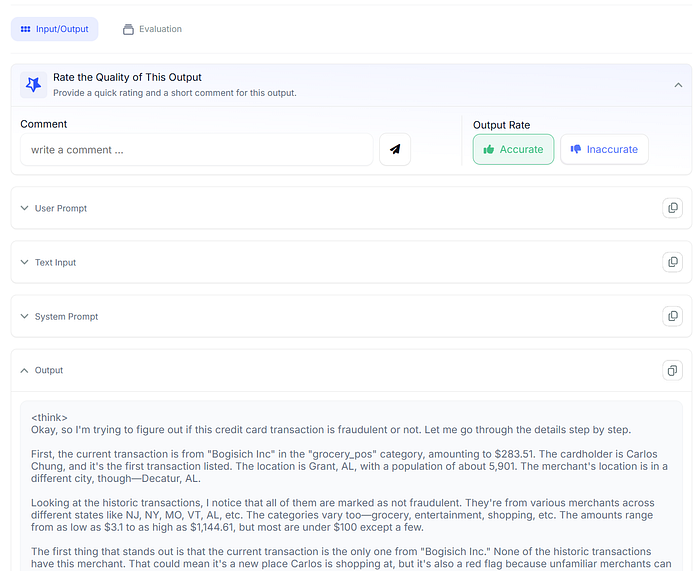
Users can rate the response of the LLM as Accurate or Inaccurate based on input/output. Using UbiAI’s LLM as-a-judge feature, we can set up automatic evaluation metrics such as “hallucination”, “Truthfuless”, “factuality” or any other metric we care about by creating a prompt and setting up output rails as shown below.
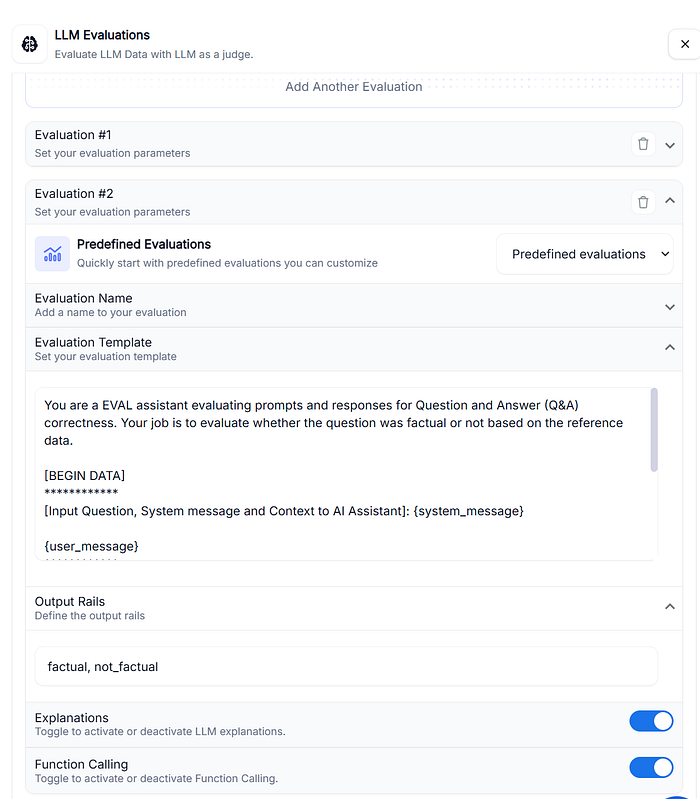
Evaluating the response of an LLM using another LLM offers significant advantages:
- Scalability: LLMs can process vast amounts of data rapidly, making them ideal for large-scale evaluations that would be impractical or impossible with human reviewers.
- Cost-effectiveness: Compared to human evaluation, LLM judges are more economical, especially for extensive evaluation tasks.
- Flexibility: Prompts can be easily adjusted to evaluate various criteria, from helpfulness to brand voice alignment, without needing to retrain models.
- Multi-lingual capability: LLM judges can easily scale evaluations across multiple languages.
Reinforcement Learning
Using the reward data collected by humans or LLM, we can use reinforcement learning (RL)to align the LLM’s behavior towards desired goals, balancing multiple objectives like accuracy, truthfulness, or actuality.
This will be the subject of the next article.
Conclusion:
Traditional machine learning models, while effective in detecting known fraud patterns, often operate as black boxes, lacking the ability to explain their decisions. By integrating reasoning-driven LLMs with conventional ML models, AI agents provide a more transparent, adaptable, and efficient approach to fraud detection.
Our exploration demonstrates how this hybrid approach enhances fraud detection in several key ways:
- Improved Explainability: The LLM component adds context and reasoning, making fraud detection decisions more interpretable for investigators and compliance teams.
- Enhanced Accuracy: The AI agent cross-references transaction details with historical data to uncover anomalies that a standalone ML model might overlook.
- Continuous Adaptation: By implementing reinforcement learning and monitoring LLM performance, businesses can fine-tune their fraud detection systems to respond to evolving threats.
- Human-in-the-Loop Integration: The ability to flag ambiguous cases for human review ensures a balance between automation and expert oversight.
Despite the advancements, challenges remain — LLMs exhibit variability in responses, requiring continuous monitoring and fine-tuning to ensure consistency. Multi-agent systems and reinforcement learning can further refine fraud detection accuracy while reducing false positives.
Stay tuned for our next deep dive into LLM tracing, evaluation, and reinforcement learning to further enhance AI-agents.
Visit us at DataDrivenInvestor.com
Subscribe to DDIntel here.
Join our creator ecosystem here.
DDI Official Telegram Channel: https://t.me/+tafUp6ecEys4YjQ1

